Our Machine Learning Models
XG Boost
XGBoost is an extension to gradient boosted decision trees (GBM) and specially designed to improve speed and performance. It implements Machine Learning algorithms under the Gradient Boosting framework, and it provides parallel tree boosting to solve many data science problems in a fast and accurate way.
XGBoost Results:
Here we have a confusion matrix with the results of the linear regression applied on our testing dataset. A confusion matrix for a classification problem tells us the number of correct and incorrect predictions for every class(Exited or Non- Exited). XgBoost performed well on the dataset.
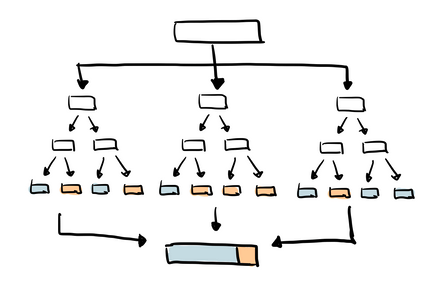
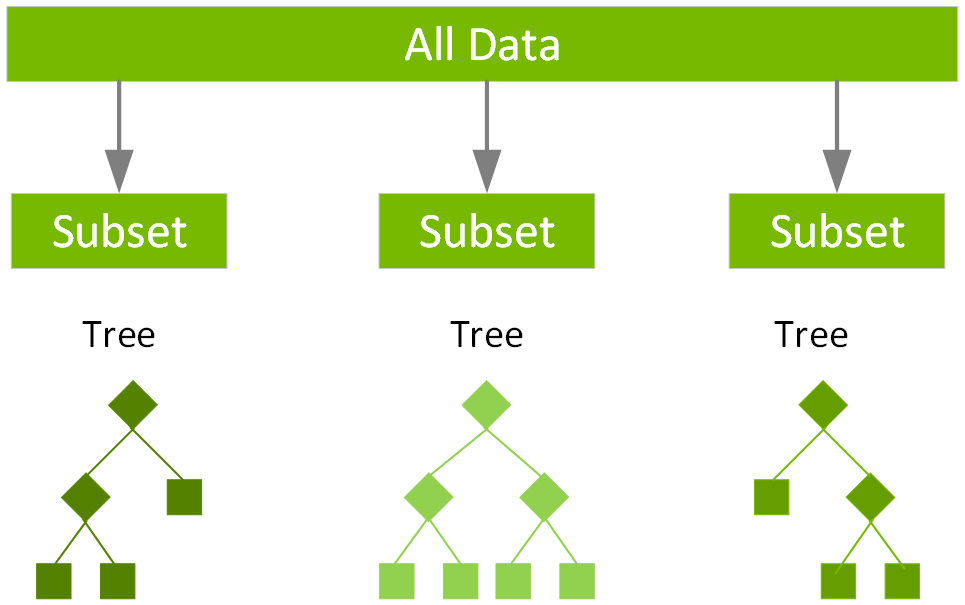
Random Forest Classifier
We use Random Forest Classification in order to address the issue of 'over-fitting' that a single tree may exhibit; so by using multiple decision trees it's able to vote on the most common classification. Random forest uses a technique called bagging to build full decision trees in parallel from random bootstrap samples of the data set. The final prediction is an average of all of the decision tree predictions. They're generally more accurate than single decision trees, but also more memory-consuming.
Random Forest Results:
Here is the confusion matrix that shows the results from Random Forest Classifier. This matrix had a lower correlation than the other models.
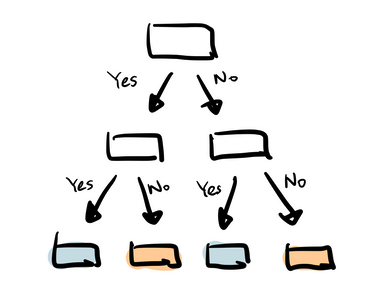
Decision Tree Classifier
Decision Tree Classifier builds branches of if-else statements in a hierarchy, and develops the data by dividing it based on the data's most important features, which makes it simpler and easier to understand, but sometimes decision trees can contain algorithms that become too complex to calculate.
Decision Tree Results:
Here is the confusion matrix that shows the results from Decision Tree Classifier, and this matrix performed slightly better than the Random Forest confusion matrix, but had about the same performance as Support Vector Classifier.
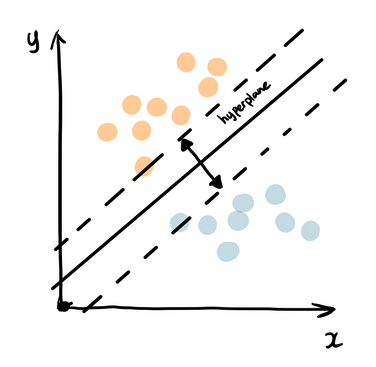
Support Vector Classifier
Support Vector Classifier uses an algorithm that splits the data given apart on a border called the hyperplane, separating the data into classes, which can make it capture complex relationship between certain features in our data.
SVM Results:
Here is the confusion matrix that shows the results from the Support Vector Classifier, and this matrix's performance was subpar in this dataset.